ARCHEOLOG-HOME / INDIana-UNIversitas
Contact























New signs of language surface in mystery Voynich text

Lisa Grossman
A mysterious and beautiful 15th-century text that some researchers have recently deemed to be gibberish may not be a hoax after all. A new study suggests the text shares quantifiable features with genuine language, and so may contain a coded message.
That verdict emerges from a statistical technique that puts a figure on the information content of elements in a text or code, even if their meaning is unknown. The technique could also be used to determine whether there is meaning in genomes, possible messages from aliens or even the signals between neurons in the brain.
The Voynich manuscript has baffled and captivated researchers since book dealer Wilfred Voynich found it in an Italian monastery in 1912. It contains illustrations of naked nymphs, unidentifiable plants, astrological diagrams and pages and pages of text in an unidentified alphabet.

Although the patterns of word lengths and symbol combinations in the text are similar to those in real languages, several recent studies have suggested that the book was a clever 15th-century hoax designed to dupe Renaissance book collectors, and that the words have no meaning. One study showed that techniques known to 16th-century cryptographers would have allowed someone to create these patterns using a nonsense set of characters. Another study concluded that the statistical properties of the script are consistent with gibberish.
Word entropy
Now Marcelo Montemurro of the University of Manchester in the UK and colleagues have analysed the text using a technique that pulls out the most meaningful terms. "We decided that's ideal to use in this mysterious manuscript," Montemurro says. "People have been discussing and quarrelling for decades about whether it's a hoax. This would be a new approach."
Their results support the idea that Voynich text really does contain a secret message.

Rather than looking for patterns in the words themselves, Montemurro's method looks for more global patterns in the frequency and clustering of words that might indicate meaning. "The results that we get looking at these things cast a new light on the content of the volume," Montemurro says.
The method uses a formula to find the entropy of each term – a measure of how evenly distributed it is. For a given term, the researchers determined its entropy in both the original text and in a scrambled version. The difference between the two entropies, multiplied by the frequency of the word, gives a measure of how much information it carries.
The method recognises that words that are particularly important will appear more frequently, as well as making a distinction between low-information words like and, which you would expect to be sprinkled evenly throughout, and high-information ones like language, which might only appear in sections dealing with that topic.
Relatedness score

Back in 2009, the entropy approach homed in on meaningful words in famous texts across several languages. In On the Origin of Species, for example, the top 10 most informative words identified by the formula included species,varieties, hybrids, forms and genera. In Moby Dick, one of the most important words, according to the formula, was whale.
When applied to Voynich, the formula picked out several high-entropy words that seemed to be specific to different sections of the manuscript.
The team also applied a further analysis that deduces how related unknown words are, based on how related words cluster in known languages. Then they used this relatedness score to compare different sections of the manuscript.
They found that the high-entropy terms in what the manuscript's illustrations would suggest are the pharmaceutical and herbal sections of the book were more likely to be related to each other than to terms in sections apparently about astrology, biology and recipes.
"They're the strongest connected linguistically and also at the level of their pictorial representations – they're the only two sections that have these plants," Montemurro says. "Our analysis is the first one that actually links these sections only by their linguistic structure."
Word clusters
The technique also measured the optimal way to cluster related words so as to maximise their information value. In novels or chapters that pertain to a certain topic, clusters of related, high-entropy terms tend to be fairly large, containing several hundred words. By contrast, on books that are simply a list of citations, say, with no connection to each other at all, clusters of related words – known as scale domains – would be much smaller.
Montemurro and colleagues compared the scale domains of the Voynich manuscript to those in texts of similar lengths in several languages: On the Origin of Species (in English), Records of the Grand Historian (Chinese), The Confessions of St. Augustine (Latin), plus computer code in the Fortran programming language and sections of yeast DNA.
The scale domain of the human languages was between 500 and 700 words in size, while Fortran's was around 300 and yeast's more like 10. For "Voynichese", it was around 800.
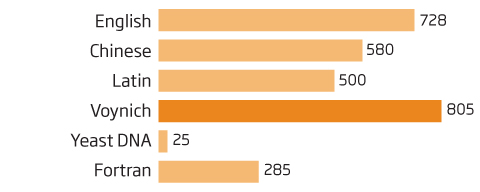
"We wanted to see whether the structure that emerged from the analysis would be consistent or not with a real language," Montemurro says. "Should we have found something like the yeast, then it would cast more doubts on the nature of the Voynich manuscript. But given the value we obtained, we say we cannot disregard that it is language."
Proponents of the hoax hypothesis are still not convinced. In 2004, computer scientist Gordon Rugg of Keele University in the UK proposed a low-tech method for a smart trickster to create the entire Voynich manuscript without first inventing a secret language.
{kind=link}
The hoaxer could first have written down a table of gibberish syllables containing the roots, prefixes and suffixes found in Voynichese, and then covered the table with a piece of card containing three holes, moving it over the table to read off new "words". Using different cards with different arrangements of holes would produce text that looked like language, even though it wasn't.
"The hoax would be perfectly feasible," Rugg says, and could produce several of the features that Montemurro found in the distribution of words in the Voynich manuscript. "A complex surface structure does not have to be produced by complex deep structure. You can have very simple processes that produce very complex outputs."
He adds that this effort might well have been warranted given the sophistication of the book collectors of the time, who might well have run some linguistic tests on a text before purchasing it.
Rugg also points out that manuscript shows no evidence of any errors having been corrected as it was written. "If the Voynich manuscript contained a real language, either the person who wrote it didn't care about having mistakes in it, or he wrote 200 pages without making a mistake," he says. "That's unlikely."
Montemurro now hopes to analyse other information-carrying sequences that are not necessarily language, such as DNA or perhaps even neural signals. This might help geneticists home in on the most valuable stretches of DNA and reveal whether different parts of the brain "speak" to each other in a code.
"But [the Voynich manuscript] does have a fascination, because for one thing, there's no closure," Rugg admits. "It's like the most interesting whodunnit ever, and somebody's ripped out the last three pages."
Journal reference: PLoS One, DOI: 10.1371/journal.pone.0066344